Golang
Begin
- 执行入口是
main()方法。 - 区分大小写。
- 每行自动加分号,不能多个语句写在一行。
- 定义的非全局变量或者import的包如果没有使用到,会报错。
- 每个Go应用程序都包含一个名为main的包。
- 编译
go build和运行go run - 起始大括号不能独占一行,否则报错。
- 注释和C语言一样。
gofmt -w格式化代码。
变量与常量
变量
声明
- 必须先声明再使用。
var 变量名 变量类型
// 批量声明
var (
name string
age int
isOK bool
)
// 类型推导
var age = 18
// 简短变量声明(只能在函数中使用)
name := "hahaha"
// 匿名变量
// 如果需要忽略某个值,用于占位。不占用命名空间,不分配内存。
// 打印
fmt.Printf("name: %s\n", name)
fmt.Print()
fmt.Println()
常量
声明
const pi = 3.14
const (
a = 100
b = 200
)
const (
n1 = 100
n2
n3
)
IOTA
iota是go语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
const (
n1 = iota //0
n2 //1
n3 //2
n4 //3
)
const (
n1 = iota //0
n2 //1
_
n4 //3
)
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2
n4 //3
)
const n5 = iota //0
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3
e, f //3,4
)
// 定义数量级
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
数据类型
进制
// 十进制
var a int = 10
fmt.Printf("%d \n", a) // 10
fmt.Printf("%b \n", a) // 1010 占位符%b表示二进制
// 八进制 以0开头
var b int = 077
fmt.Printf("%o \n", b) // 77
// 十六进制 以0x开头
var c int = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
// 查看变量类型 %T
// 强制类型转换 int8(num)
// 占位符
// T, v, b, d, o, x, s, #v
整型
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64
| 类型 | 描述 |
|---|---|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
浮点型
Go语言支持两种浮点型数:float32和float64。
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi)
fmt.Printf("%.2f\n", math.Pi)
}
// 默认float64,显式声明float32
f := float32(1.2345)
// 32和64不能直接互相赋值
复数
complex64和complex128
var c1 complex64
c1 = 1 + 2i
var c2 complex128
c2 = 2 + 3i
fmt.Println(c1)
fmt.Println(c2)
复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
bool
- 布尔类型变量的默认值为false。
- Go 语言中不允许将整型强制转换为布尔型.
- 布尔型无法参与数值运算,也无法与其他类型进行转换。
字符串
- 只能用双引号,使用UTF8
转义字符
| 转义符 | 含义 |
|---|---|
| \r | 回车符(返回行首) |
| \n | 换行符(直接跳到下一行的同列位置) |
| \t | 制表符 |
| \' | 单引号 |
| \" | 双引号 |
| \\ | 反斜杠 |
多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
相关操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位 |
| strings.Join(a[]string, sep string) | join操作 |
字符
Go 语言的字符有以下两种:
- uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。
- rune类型,代表一个 UTF-8字符。
// 遍历字符串
func traversalString() {
s := "hello"
for i := 0; i < len(s); i++ { //byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}
修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func changeString() {
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "白萝卜"
runeS2 := []rune(s2)
runeS2[0] = '红'
fmt.Println(string(runeS2))
}
类型转换
Go语言中只有强制类型转换,没有隐式类型转换。
func sqrtDemo() {
var a, b = 3, 4
var c int
// math.Sqrt()接收的参数是float64类型,需要强制转换
c = int(math.Sqrt(float64(a*a + b*b)))
fmt.Println(c)
}
流程控制
if
if 表达式1 {
分支1
} else if 表达式2 {
分支2
} else{
分支3
}
// if条件判断还有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断。
if score := 65; score >= 90 {
fmt.Println("A")
} else if score > 75 {
fmt.Println("B")
} else {
fmt.Println("C")
}
for
func forDemo() {
for i := 0; i < 10; i++ {
fmt.Println(i)
}
}
// 无限循环
for {
循环体语句
}
// for range
s := "Hello"
for i, v := range s {
fmt.Printf("%d %c\n", i, v)
}
switch
func switchDemo1() {
finger := 3
switch finger {
case 1:
fmt.Println("大拇指")
case 2:
fmt.Println("食指")
case 3:
fmt.Println("中指")
case 4:
fmt.Println("无名指")
case 5:
fmt.Println("小拇指")
default:
fmt.Println("无效的输入!")
}
}
// Go语言规定每个switch只能有一个default分支。
// 一个分支可以有多个值,多个case值中间使用英文逗号分隔。
func testSwitch3() {
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
}
// 分支还可以使用表达式,这时候switch语句后面不需要再跟判断变量。例如:
func switchDemo4() {
age := 30
switch {
case age < 25:
fmt.Println("好好学习吧")
case age > 25 && age < 35:
fmt.Println("好好工作吧")
case age > 60:
fmt.Println("好好享受吧")
default:
fmt.Println("活着真好")
}
}
// fallthrough语法可以执行满足条件的case的下一个case,是为了兼容C语言中的case设计的。
func switchDemo5() {
s := "a"
switch {
case s == "a":
fmt.Println("a")
fallthrough
case s == "b":
fmt.Println("b")
case s == "c":
fmt.Println("c")
default:
fmt.Println("...")
}
}
运算符
++(自增)和–(自减)在Go语言中是单独的语句,并不是运算符。
数组
// 定义一个长度为3元素类型为int的数组a
var a [3]int
// 初始化
var testArray [3]int //数组会初始化为int类型的零值
var numArray = [3]int{1, 2} //使用指定的初始值完成初始化
var cityArray = [3]string{"北京", "上海", "深圳"} //使用指定的初始值完成初始化
// 编译器根据初始值的个数自行推断数组的长度
var testArray [3]int
var numArray = [...]int{1, 2}
var cityArray = [...]string{"北京", "上海", "深圳"}
// 使用索引
a := [...]int{1: 1, 3: 5}
// 遍历
func main() {
var a = [...]string{"北京", "上海", "深圳"}
// 方法1:for循环遍历
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
// 方法2:for range遍历
for index, value := range a {
fmt.Println(index, value)
}
}
// 二维数组
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
fmt.Println(a) //[[北京 上海] [广州 深圳] [成都 重庆]]
fmt.Println(a[2][1]) //支持索引取值:重庆
}
// 二维数组的遍历
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
for _, v1 := range a {
for _, v2 := range v1 {
fmt.Printf("%s\t", v2)
}
fmt.Println()
}
}
// 多维数组只有第一层可以使用...来让编译器推导数组长度。
切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
var s []int
// 1. 初始化
s = []int{1, 2, 3}
// 2. 由数组进行切割得到
a := [5]int{1, 2, 3, 4, 5}
t := a[1:3]
// 3. make()初始化
make([]T, size, cap)
/*
T:切片的元素类型
size:切片中元素的数量
cap:切片的容量
*/
func main() {
a := make([]int, 2, 10)
fmt.Println(a) //[0 0]
fmt.Println(len(a)) //2
fmt.Println(cap(a)) //10
}
切片表达式
// 切片是引用类型,都指向一个底层数组
// 左闭右开
a[2:] // 等同于 a[2:len(a)]
a[:3] // 等同于 a[0:3]
a[:] // 等同于 a[0:len(a)]
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求长度,使用内置的cap()函数求切片的容量。
容量是指切片的底层数组指向的第一个元素到最后的长度。
判断是否为空
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。 切片唯一合法的比较操作是和nil比较。 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil。
append()添加元素
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
func main(){
var s []int
// 必须用变量接收append返回值
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
}
注意:通过var声明的零值切片可以在append()函数直接使用,无需初始化。
var s []int
s = append(s, 1, 2, 3)
没有必要像下面的代码一样初始化一个切片再传入append()函数使用,
s := []int{} // 没有必要初始化
s = append(s, 1, 2, 3)
var s = make([]int) // 没有必要初始化
s = append(s, 1, 2, 3)
每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
切片numSlice的容量按照1,2,4,8,16这样的规则自动进行扩容,每次扩容后都是扩容前的2倍。
copy()复制切片
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T)
// srcSlice: 数据来源切片
// destSlice: 目标切片
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //使用copy()函数将切片a中的元素复制到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}
切片中删除元素
func main() {
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
}
要从切片a中删除索引为index的元素,操作方法是
a = append(a[:index], a[index+1:]...)
指针
取值和传值
&:取地址。
*:根据地址取值。
func main() {
//指针取值
a := 10
b := &a // 取变量a的地址,将指针保存到b中
fmt.Printf("type of b:%T\n", b)
c := *b // 指针取值(根据指针去内存取值)
fmt.Printf("type of c:%T\n", c)
fmt.Printf("value of c:%v\n", c)
}
// 指针传值
func modify1(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
func main() {
a := 10
modify1(a)
fmt.Println(a) // 10
modify2(&a)
fmt.Println(a) // 100
}
new和make
new
使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
func main() {
var a *int
a = new(int)
*a = 10
fmt.Println(*a)
}
make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。
func main() {
var b map[string]int
b = make(map[string]int, 10)
b["Hello"] = 100
fmt.Println(b)
}
map
定义
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。内部使用散列表(hash)实现。
使用
map类型的变量默认初始值为nil,需要使用make()函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])
其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
func main() {
scoreMap := make(map[string]int, 8)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
fmt.Println(scoreMap)
fmt.Println(scoreMap["小明"])
fmt.Printf("type of a:%T\n", scoreMap)
}
func main() {
userInfo := map[string]string{
"username": "name",
"password": "123456",
}
fmt.Println(userInfo)
}
判断键是否存在
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
// 如果key存在ok为true,v为对应的值;不存在ok为false,v为值类型的零值
v, ok := scoreMap["张三"]
if ok {
fmt.Println(v)
} else {
fmt.Println("查无此人")
}
}
遍历
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["娜扎"] = 60
for k, v := range scoreMap {
fmt.Println(k, v)
}
}
// 只想遍历key的时候,如下
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["李四"] = 60
for k := range scoreMap {
fmt.Println(k)
}
}
删除某键值对
func main(){
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["李四"] = 60
delete(scoreMap, "小明")//将小明:100从map中删除
for k,v := range scoreMap{
fmt.Println(k, v)
}
}
按指定顺序遍历
func main() {
rand.Seed(time.Now().UnixNano()) //初始化随机数种子
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串
value := rand.Intn(100) //生成0~99的随机整数
scoreMap[key] = value
}
//取出map中的所有key存入切片keys
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
//对切片进行排序
sort.Strings(keys)
//按照排序后的key遍历map
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}
}
map和切片
// 切片中的元素为map类型时的操作
func main() {
var mapSlice = make([]map[string]string, 3)
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "小王子"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "中国"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}
// map中值为切片类型的操作
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
函数
定义和参数
func 函数名(参数)(返回值){
函数体
}
func intSum(x int, y int) int {
return x + y
}
func sayHello() {
fmt.Println("Hello 沙河")
}
// 函数的参数中如果相邻变量的类型相同,则可以省略类型。
func intSum(x, y int) int {
return x + y
}
// 可变参数
// 可变参数是指函数的参数数量不固定。Go语言中的可变参数通过在参数名后加...来标识。
// 可变参数通常要作为函数的最后一个参数。
func intSum2(x ...int) int {
fmt.Println(x) //x是一个切片
sum := 0
for _, v := range x {
sum = sum + v
}
return sum
}
// 固定参数搭配可变参数使用时,可变参数要放在固定参数的后面。
func intSum3(x int, y ...int) int {
fmt.Println(x, y)
sum := x
for _, v := range y {
sum = sum + v
}
return sum
}
返回值
// 多返回值
// Go语言中函数支持多返回值,函数如果有多个返回值时必须用()将所有返回值包裹起来。
func calc(x, y int) (int, int) {
sum := x + y
sub := x - y
return sum, sub
}
// 返回值命名
// 函数定义时可以给返回值命名,并在函数体中直接使用这些变量,最后通过return关键字返回。
func calc(x, y int) (sum, sub int) {
sum = x + y
sub = x - y
return
}
// 返回值补充
// 当我们的一个函数返回值类型为slice时,nil可以看做是一个有效的slice,没必要显示返回一个长度为0的切片。
func someFunc(x string) []int {
if x == "" {
return nil // 没必要返回[]int{}
}
...
}
函数类型与变量
// 定义函数类型
type calculation func(int, int) int
// 上面语句定义了一个calculation类型,它是一种函数类型,这种函数接收两个int类型的参数并且返回一个int类型的返回值。
// 简单来说,凡是满足这个条件的函数都是calculation类型的函数,例如下面的add和sub是calculation类型。
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
// add和sub都能赋值给calculation类型的变量。
var c calculation
c = add
// 函数类型变量
// 我们可以声明函数类型的变量并且为该变量赋值。
func main() {
var c calculation // 声明一个calculation类型的变量c
c = add // 把add赋值给c
fmt.Printf("type of c:%T\n", c) // type of c:main.calculation
fmt.Println(c(1, 2)) // 像调用add一样调用c
f := add // 将函数add赋值给变量f1
fmt.Printf("type of f:%T\n", f) // type of f:func(int, int) int
fmt.Println(f(10, 20)) // 像调用add一样调用f
}
函数作为参数和返回值
// 函数作为参数
func add(x, y int) int {
return x + y
}
func calc(x, y int, op func(int, int) int) int {
return op(x, y)
}
func main() {
ret2 := calc(10, 20, add)
fmt.Println(ret2) //30
}
// 函数作为返回值
func do(s string) (func(int, int) int, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("无法识别的操作符")
return nil, err
}
}
匿名函数和闭包
// 匿名函数就是没有函数名的函数
func main() {
// 将匿名函数保存到变量
add := func(x, y int) {
fmt.Println(x + y)
}
add(10, 20) // 通过变量调用匿名函数
//自执行函数:匿名函数定义完加()直接执行
func(x, y int) {
fmt.Println(x + y)
}(10, 20)
}
// 闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境。
// Example1
func adder() func(int) int {
var x int
return func(y int) int {
x += y
return x
}
}
func main() {
var f = adder()
fmt.Println(f(10)) //10
fmt.Println(f(20)) //30
fmt.Println(f(30)) //60
f1 := adder()
fmt.Println(f1(40)) //40
fmt.Println(f1(50)) //90
}
// Example2
func makeSuffixFunc(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
func main() {
jpgFunc := makeSuffixFunc(".jpg")
txtFunc := makeSuffixFunc(".txt")
fmt.Println(jpgFunc("test")) //test.jpg
fmt.Println(txtFunc("test")) //test.txt
}
defer语句
Go语言中的defer语句会将其后面跟随的语句进行延迟处理。在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句,最先被执行。
func main() {
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end")
}
输出结果:
start
end
3
2
1
由于defer语句延迟调用的特性,所以defer语句能非常方便的处理资源释放问题。比如:资源清理、文件关闭、解锁及记录时间等。
内置函数
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到数组、slice中 |
| panic和recover | 用来做错误处理 |
结构体
自定义类型
//将MyInt定义为int类型
type MyInt int
类型别名
type TypeAlias = Type
// rune和byte就是类型别名,他们的定义如下:
type byte = uint8
type rune = int32
// 自定义类型和类型别名区别
//类型定义
type NewInt int
//类型别名
type MyInt = int
func main() {
var a NewInt
var b MyInt
fmt.Printf("type of a:%T\n", a) //type of a:main.NewInt
fmt.Printf("type of b:%T\n", b) //type of b:int
}
定义结构体
type person struct {
name string
city string
age int8
}
// 同样类型的字段也可以写在一行
type person1 struct {
name, city string
age int8
}
结构体实例化
// 基本实例化
type person struct {
name string
city string
age int8
}
func main() {
var p1 person
p1.name = "小明"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) //p1={小明 北京 18}
fmt.Printf("p1=%#v\n", p1) //p1=main.person{name:"小明", city:"北京", age:18}
}
// 匿名结构体
func main() {
var user struct{Name string; Age int}
user.Name = "小王子"
user.Age = 18
fmt.Printf("%#v\n", user)
}
// 创建指针类型结构体
var p2 = new(person)
p2.name = "小王子"
p2.age = 28
p2.city = "上海"
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"小王子", city:"上海", age:28}
// 取结构体的地址实例化
p3 := &person{}
fmt.Printf("%T\n", p3) //*main.person
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"", city:"", age:0}
p3.name = "七米"
p3.age = 30
p3.city = "成都"
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"七米", city:"成都", age:30}
结构体初始化
// 使用键值对初始化
p5 := person{
name: "小王子",
city: "北京",
age: 18,
}
// 对结构体指针进行键值对初始化
p6 := &person{
name: "小王子",
city: "北京",
age: 18,
}
// 当某些字段没有初始值的时候,该字段可以不写。此时,没有指定初始值的字段的值就是该字段类型的零值。
// 使用值的列表初始化
p8 := &person{
"小明",
"北京",
28,
}
// 使用这种格式初始化时,需要注意:
// 必须初始化结构体的所有字段。
// 初始值的填充顺序必须与字段在结构体中的声明顺序一致。
// 该方式不能和键值初始化方式混用。
构造函数
Go语言的结构体没有构造函数,我们可以自己实现。 例如,下方的代码就实现了一个person的构造函数。 因为struct是值类型,如果结构体比较复杂的话,值拷贝性能开销会比较大,所以该构造函数返回的是结构体指针类型。
func newPerson(name, city string, age int8) *person {
return &person{
name: name,
city: city,
age: age,
}
}
方法和接收者
Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。接收者的概念就类似于其他语言中的this或者 self。
// 使用指针接收者
func (p *Person) SetAge(newAge int8) {
p.age = newAge
}
func main() {
p1 := NewPerson("小王子", 25)
fmt.Println(p1.age) // 25
p1.SetAge(30)
fmt.Println(p1.age) // 30
}
// 使用值接收者
func (p Person) SetAge2(newAge int8) {
p.age = newAge
}
func main() {
p1 := NewPerson("小王子", 25)
p1.Dream()
fmt.Println(p1.age) // 25
p1.SetAge2(30) // (*p1).SetAge2(30)
fmt.Println(p1.age) // 25
}
任意类型添加方法
在Go语言中,接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。 举个例子,我们基于内置的int类型使用type关键字可以定义新的自定义类型,然后为我们的自定义类型添加方法。
//MyInt 将int定义为自定义MyInt类型
type MyInt int
//SayHello 为MyInt添加一个SayHello的方法
func (m MyInt) SayHello() {
fmt.Println("Hello, 我是一个int。")
}
func main() {
var m1 MyInt
m1.SayHello() //Hello, 我是一个int。
m1 = 100
fmt.Printf("%#v %T\n", m1, m1) //100 main.MyInt
}
结构体的匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段。
//Person 结构体Person类型
type Person struct {
string
int
}
func main() {
p1 := Person{
"小王子",
18,
}
fmt.Printf("%#v\n", p1) //main.Person{string:"北京", int:18}
fmt.Println(p1.string, p1.int) //北京 18
}
这里匿名字段的说法并不代表没有字段名,而是默认会采用类型名作为字段名,结构体要求字段名称必须唯一,因此一个结构体中同种类型的匿名字段只能有一个。
结构体的继承
//Animal 动物
type Animal struct {
name string
}
func (a *Animal) move() {
fmt.Printf("%s会动!\n", a.name)
}
//Dog 狗
type Dog struct {
Feet int8
*Animal //通过嵌套匿名结构体实现继承
}
func (d *Dog) wang() {
fmt.Printf("%s会汪汪汪~\n", d.name)
}
func main() {
d1 := &Dog{
Feet: 4,
Animal: &Animal{ //注意嵌套的是结构体指针
name: "乐乐",
},
}
d1.wang() //乐乐会汪汪汪~
d1.move() //乐乐会动!
}
结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问)。
接口
定义和使用
// 接口的定义
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
type writer interface{
Write([]byte) error
}
// 接口的实现
// Sayer 接口
type Sayer interface {
say()
}
type dog struct {}
type cat struct {}
// dog实现了Sayer接口
func (d dog) say() {
fmt.Println("汪汪汪")
}
// cat实现了Sayer接口
func (c cat) say() {
fmt.Println("喵喵喵")
}
// 接口类型变量
接口类型变量能够存储所有实现了该接口的实例。 例如上面的示例中,Sayer类型的变量能够存储dog和cat类型的变量。
func main() {
var x Sayer // 声明一个Sayer类型的变量x
a := cat{} // 实例化一个cat
b := dog{} // 实例化一个dog
x = a // 可以把cat实例直接赋值给x
x.say() // 喵喵喵
x = b // 可以把dog实例直接赋值给x
x.say() // 汪汪汪
}
接口嵌套
接口与接口间可以通过嵌套创造出新的接口。
// Sayer 接口
type Sayer interface {
say()
}
// Mover 接口
type Mover interface {
move()
}
// 接口嵌套
type animal interface {
Sayer
Mover
}
空接口
// 使用空接口实现可以接收任意类型的函数参数。
// 空接口作为函数参数
func show(a interface{}) {
fmt.Printf("type:%T value:%v\n", a, a)
}
// 使用空接口实现可以保存任意值的字典。
// 空接口作为map值
var studentInfo = make(map[string]interface{})
studentInfo["name"] = "小明"
studentInfo["age"] = 18
studentInfo["married"] = false
fmt.Println(studentInfo)
类型断言
想要判断空接口中的值这个时候就可以使用类型断言,其语法格式:
x.(T)
其中:
- x:表示类型为interface{}的变量
- T:表示断言x可能是的类型。
该语法返回两个参数,第一个参数是x转化为T类型后的变量,第二个值是一个布尔值,若为true则表示断言成功,为false则表示断言失败。
func main() {
var x interface{}
x = "Hello"
v, ok := x.(string)
if ok {
fmt.Println(v)
} else {
fmt.Println("类型断言失败")
}
}
包
定义包
package 包名
- 一个文件夹下面直接包含的文件只能归属一个package,同样一个package的文件不能在多个文件夹下。
- 包名可以不和文件夹的名字一样,包名不能包含 - 符号。
- 包名为main的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含main包的源代码则不会得到可执行文件。
可见性
如果想在一个包中引用另外一个包里的标识符(如变量、常量、类型、函数等)时,该标识符必须是对外可见的(public)。在Go语言中只需要将标识符的首字母大写就可以让标识符对外可见了。
导入
// 单行导入
import "包1"
// 多行导入
import (
"包1"
"包2"
)
别名
// 单行导入方式定义别名
import "fmt"
import m "github.com/Q1mi/studygo/pkg_test"
func main() {
fmt.Println(m.Add(100, 200))
fmt.Println(m.Mode)
}
// 多行导入方式定义别
import (
"fmt"
m "github.com/Q1mi/studygo/pkg_test"
)
func main() {
fmt.Println(m.Add(100, 200))
fmt.Println(m.Mode)
}
匿名导入包
如果只希望导入包,而不使用包内部的数据时,可以使用匿名导入包。
import _ "包的路径"
init()初始化函数
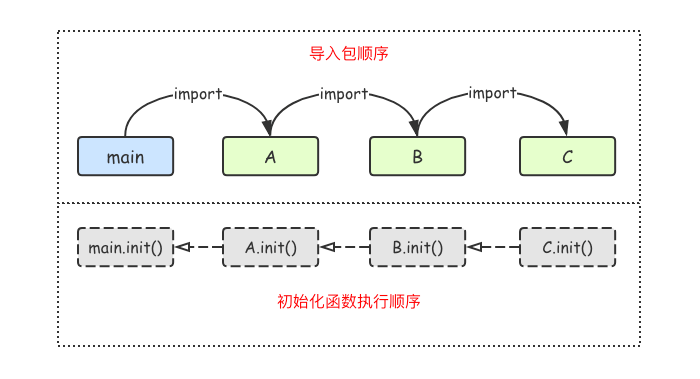
在Go语言程序执行时导入包语句会自动触发包内部init()函数的调用。需要注意的是: init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它。
反射
反射是指在程序运行期对程序本身进行访问和修改的能力。
Go程序在运行期使用reflect包访问程序的反射信息。reflect包提供了reflect.TypeOf和reflect.ValueOf两个函数来获取任意对象的Value和Type。
使用reflect.TypeOf()函数可以获得任意值的类型对象(reflect.Type),程序通过类型对象可以访问任意值的类型信息。
反射中关于类型还划分为两种:类型(Type)和种类(Kind)。种类(Kind)指底层的类型。
reflect.ValueOf()返回的是reflect.Value类型,其中包含了原始值的值信息。reflect.Value与原始值之间可以互相转换。
反射中使用专有的Elem()方法来获取指针对应的值。
并发
Go语言的并发通过goroutine实现。goroutine类似于线程,属于用户态的线程,我们可以根据需要创建成千上万个goroutine并发工作。goroutine是由Go语言的运行时(runtime)调度完成,而线程是由操作系统调度完成。
goroutine
使用goroutine
Go语言中使用goroutine只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。
一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
启动单个goroutine
func main() {
go hello() // 启动另外一个goroutine去执行hello函数
fmt.Println("main goroutine done!")
time.Sleep(time.Second)
}
启动多个goroutine
使用了sync.WaitGroup来实现goroutine的同步
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done() // goroutine结束就登记-1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 启动一个goroutine就登记+1
go hello(i)
}
wg.Wait() // 等待所有登记的goroutine都结束
}
goroutine在对应函数结束时才结束。
Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。
channel
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。
创建channel
通道是引用类型,通道类型的空值是nil。
var ch chan int
fmt.Println(ch) // <nil>
声明的通道后需要使用make函数初始化之后才能使用。
创建channel的格式如下:
make(chan 元素类型, [缓冲大小])
// channel的缓冲大小是可选的
ch4 := make(chan int)
ch5 := make(chan bool)
ch6 := make(chan []int)
channel操作
通道有发送(send)、接收(receive)和关闭(close)三种操作。
发送和接收都使用<-符号。
ch := make(chan int)
// 发送
ch <- 10 // 把10发送到ch中
// 接收
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果
// 关闭
close(ch)
无缓冲的通道
使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道。
有缓冲的通道
我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量。
单向通道
限制通道在函数中只能发送或只能接收。
worker pool(goroutine池)
在工作中通常会使用可以指定启动的goroutine数量–worker pool模式,控制goroutine的数量,防止goroutine泄漏和暴涨。
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Printf("worker:%d start job:%d\n", id, j)
time.Sleep(time.Second)
fmt.Printf("worker:%d end job:%d\n", id, j)
results <- j * 2
}
}
func main() {
jobs := make(chan int, 100)
results := make(chan int, 100)
// 开启3个goroutine
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// 5个任务
for j := 1; j <= 5; j++ {
jobs <- j
}
close(jobs)
// 输出结果
for a := 1; a <= 5; a++ {
<-results
}
}
select
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。
select{
case <-ch1:
...
case data := <-ch2:
...
case ch3<-data:
...
default:
默认操作
}
func main() {
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch:
fmt.Println(x)
case ch <- i:
}
}
}
并发安全和锁
存在多个goroutine同时操作一个资源(临界区)时,需要确保安全。
互斥锁
使用互斥锁能够保证同一时间有且只有一个goroutine进入临界区,其他的goroutine则在等待锁;当互斥锁释放后,等待的goroutine才可以获取锁进入临界区,多个goroutine同时等待一个锁时,唤醒的策略是随机的。
var x int64
var wg sync.WaitGroup
var lock sync.Mutex
func add() {
for i := 0; i < 5000; i++ {
lock.Lock() // 加锁
x = x + 1
lock.Unlock() // 解锁
}
wg.Done()
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
读写互斥锁
读写锁分为两种:读锁和写锁。当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
读写锁非常适合读多写少的场景,如果读和写的操作差别不大,读写锁的优势就发挥不出来。
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
rwlock sync.RWMutex
)
func write() {
// lock.Lock() // 加互斥锁
rwlock.Lock() // 加写锁
x = x + 1
time.Sleep(10 * time.Millisecond) // 假设读操作耗时10毫秒
rwlock.Unlock() // 解写锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func read() {
// lock.Lock() // 加互斥锁
rwlock.RLock() // 加读锁
time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒
rwlock.RUnlock() // 解读锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
end := time.Now()
fmt.Println(end.Sub(start))
}
sync
sync.WaitGroup
| 方法名 | 功能 |
|---|---|
| (wg * WaitGroup) Add(delta int) | 计数器+delta |
| (wg *WaitGroup) Done() | 计数器-1 |
| (wg *WaitGroup) Wait() | 阻塞直到计数器变为0 |
sync.Once
某些操作在高并发的场景下只执行一次,例如只加载一次配置文件、只关闭一次通道等。
sync.Map
Go语言中内置的map不是并发安全的。
Go语言的sync包中提供了一个开箱即用的并发安全版map–sync.Map。开箱即用表示不用像内置的map一样使用make函数初始化就能直接使用。同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
var m = sync.Map{}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
m.Store(key, n)
value, _ := m.Load(key)
fmt.Printf("k=:%v,v:=%v\n", key, value)
wg.Done()
}(i)
}
wg.Wait()
}
原子操作
Go语言中原子操作由内置的标准库sync/atomic提供。
单元测试
测试函数
每个测试函数必须导入testing包,测试函数的基本格式(签名)如下:
func TestName(t *testing.T){
// ...
}
测试函数的名字必须以Test开头,可选的后缀名必须以大写字母开头,例如:
func TestAdd(t *testing.T){ ... }
func TestSum(t *testing.T){ ... }
func TestLog(t *testing.T){ ... }
Go语言中的测试依赖go test命令。
go test命令是一个按照一定约定和组织的测试代码的驱动程序。在包目录内,所有以_test.go为后缀名的源代码文件都是go test测试的一部分,不会被go build编译到最终的可执行文件中。
在*_test.go文件中有三种类型的函数,单元测试函数、基准测试函数和示例函数。
| 类型 | 格式 | 作用 |
|---|---|---|
| 测试函数 | 函数名前缀为Test | 测试程序的一些逻辑行为是否正确 |
| 基准函数 | 函数名前缀为Benchmark | 测试函数的性能 |
| 示例函数 | 函数名前缀为Example | 为文档提供示例文档 |
go test命令会遍历所有的*_test.go文件中符合上述命名规则的函数,然后生成一个临时的main包用于调用相应的测试函数,然后构建并运行、报告测试结果,最后清理测试中生成的临时文件。
// split/split.go
package split
import "strings"
func Split(s, sep string) (result []string) {
i := strings.Index(s, sep)
for i > -1 {
result = append(result, s[:i])
s = s[i+1:]
i = strings.Index(s, sep)
}
result = append(result, s)
return
}
// split/split_test.go
package split
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) { // 测试函数名必须以Test开头,必须接收一个*testing.T类型参数
got := Split("a:b:c", ":") // 程序输出的结果
want := []string{"a", "b", "c"} // 期望的结果
if !reflect.DeepEqual(want, got) { // 因为slice不能比较直接,借助反射包中的方法比较
t.Errorf("expected:%v, got:%v", want, got) // 测试失败输出错误提示
}
}
代码覆盖率
在测试中至少被运行一次的代码占总代码的比例。
Go提供内置功能来检查你的代码覆盖率。我们可以使用go test -cover来查看测试覆盖率。
基准测试
基准测试就是在一定的工作负载之下检测程序性能的一种方法。
Setup与TearDown
测试程序有时需要在测试之前进行额外的设置(setup)或在测试之后进行拆卸(teardown)。
通过在*_test.go文件中定义TestMain函数来可以在测试之前进行额外的设置(setup)或在测试之后进行拆卸(teardown)操作。
示例函数
func ExampleSplit() {
fmt.Println(split.Split("a:b:c", ":"))
}
pprof
在计算机性能调试领域里,profiling 是指对应用程序的画像,画像就是应用程序使用 CPU 和内存的情况。
- CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据
- Memory Profile(Heap Profile):报告程序的内存使用情况
- Block Profiling:报告 goroutines 不在运行状态的情况,可以用来分析和查找死锁等性能瓶颈
- Goroutine Profiling:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的
Go语言内置了获取程序的运行数据的工具,包括以下两个标准库:
- runtime/pprof:采集工具型应用运行数据进行分析
- net/http/pprof:采集服务型应用运行时数据进行分析
pprof开启后,每隔一段时间(10ms)就会收集下当前的堆栈信息,获取各个函数占用的CPU以及内存资源;最后通过对这些采样数据进行分析,形成一个性能分析报告。,我们只应该在性能测试的时候才在代码中引入pprof。
Context
Go1.7加入了一个新的标准库context,它定义了Context类型,专门用来简化对于处理单个请求的多个 goroutine 之间与请求域的数据、取消信号、截止时间等相关操作,这些操作可能涉及多个 API 调用。
Context接口
context.Context是一个接口,该接口定义了四个需要实现的方法。具体签名如下:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
Background()和TODO()
Go内置两个函数:Background()和TODO(),这两个函数分别返回一个实现了Context接口的background和todo。我们代码中最开始都是以这两个内置的上下文对象作为最顶层的partent context,衍生出更多的子上下文对象。
Background()主要用于main函数、初始化以及测试代码中,作为Context这个树结构的最顶层的Context,也就是根Context。
TODO(),它目前还不知道具体的使用场景,如果我们不知道该使用什么Context的时候,可以使用这个。
background和todo本质上都是emptyCtx结构体类型,是一个不可取消,没有设置截止时间,没有携带任何值的Context。
四个方法
对服务器传入的请求应该创建上下文,而对服务器的传出调用应该接受上下文。它们之间的函数调用链必须传递上下文,或者可以使用WithCancel、WithDeadline、WithTimeout或WithValue创建的派生上下文。当一个上下文被取消时,它派生的所有上下文也被取消。
消息队列
同步变异步,进程之间的通信。
brew services start zookeeper
brew services stop zookeeper
zkServer start
zkServer stop
zkServer status
参考链接: